
此文是《10周入門資料分析》系列的第13篇
想瞭解學習路線,可以先閱讀 學習計畫 | 10周入門資料分析
前面經過十幾篇文章,相想必大家對於資料分析是什麼,怎麼做有了基本的認識。跟著操作的小夥伴基本功應該練的差不多了,可以蛟龍出海了。
有些基礎后,理論上的東西我們先放一放,現在開始我們就學習一下很熱門,很燙手的python》》入門版六小節,好了,跟著小編學起來吧!
作為當下最熱門的程式設計語言之一,Python有兩個非常有趣的方向:一個是資料分析,從掌握資料分析的基本方法開始,學習NumPy、Pandas、mapplotlib包;然後再往下就是資料採擷,機器學習、深度學習,甚至人工智慧。另外一個方向則是web開發。有同學說爬蟲呢,爬蟲其實是獲取資料的一個手段,包括資料庫的處理等等都是包含在上面兩條路線裡面。
想學會一門語言不是一朝一夕的事情,本文是按照業務資料分析師/商業分析師的路線來講Python的學習路徑。若大家想成為技術型的分析師,或者未來往資料採擷發展,建議你要比文章內容學得更深,所有的程式碼最好都手打一遍,這是最有效的學習方式。
好了,言歸正傳。按照所有程式設計語言的學習套路,先從基礎語法開始,有程式設計基礎的同好可能學習起來比較輕鬆,但也建議看一遍,溫習一二。
Python的編寫環境,用Anaconda足矣。Anaconda是專業的資料科學計算環境,已經集成絕大部分包和工具,不需要多餘的安裝和調試。
Python版本建議3.0以上,不要選擇2.7的版本,否則你會被無盡的中文編碼問題困擾。
Anaconda在官網下載,選擇最新版本,約400MB。
完成安裝後,Win版本會多出幾個程式,Mac版本只有一個Navigator導航。資料分析最常用的程式叫Jupyter,以前被稱為IPython Notebook,是一個互動式的筆記本,能快速創建程式,支援即時程式碼、視覺化和Markdown語言。
點擊Jupyter進入,它會自動創建一個本地環境localhost。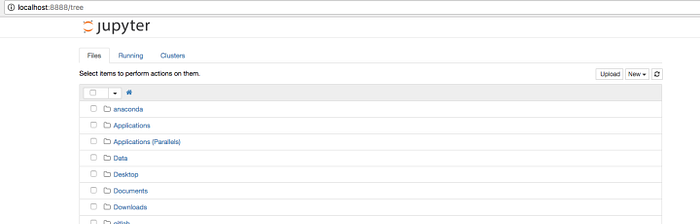
點擊介面右上角的new,創建一個python檔。
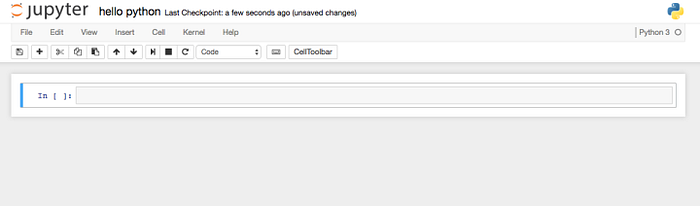
介面上部是工具列,編輯撤回運行等,下面是快捷操作,大家以後會熟悉的。頁面正中便是腳本執行的地方,我們輸入自己第一行程式碼吧:
(我就不用hello world)灰色框是輸入程式的地方,回車是換行,shift+回車執行灰色區域的程式碼,它的結果會直接在下面空白處出現。這就是Jupyter互動式的強大地方,將Python腳本分成片段式運行,尤其適合資料分析的摸索調整工作。
這裡的print叫函數,和excel的函數同理,是程式執行的主體,負責將輸入轉化成輸出(函數留在下一篇細講)。這裡將hello qinlu這段文字輸出。新手可能會奇怪為什麼要加引號,這種用引號括起來的文字在程式中叫字串。
Python是一門電腦語言,它的邏輯和自然語言不一樣,程式設計語言的目的是執行任務,所以它不能有歧義。為了規避各種歧義,人們創造了語法規則,只有正確的語法,才能被轉換成CPU執行的機器碼。
先瞭解Python語法中的資料類型。電腦最開始只被用於數值運算,後來被賦予了各種豐富的資料類型。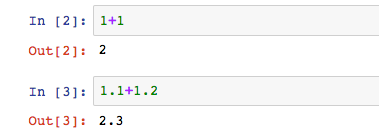
上面兩個是小學生都會的四則運算,在電腦語言中可沒有那麼簡單。它涉及了兩個數值類型,整數int和浮點數float。整數和浮點數在電腦內部存儲的方式是不同的,我們不用知道具體原理,明確一點,整數運算是永遠精確的,浮點運算則可能有誤差。
兩種資料類型也可以互換,透過int函數和float函數。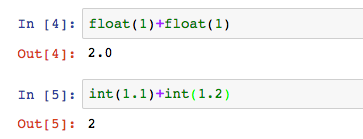
有了數值,必然有文本,程式中叫字串,用英文引號括起來表示。單引號和雙引號沒有區別,所以”qinlu”和’qinlu’是等價的,引號是邊界,輸出的時候不會包含它。當字串內本身包含引號時,也不影響使用。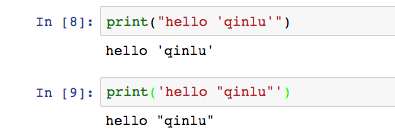
需要注意的是,不論單引號還是雙引號,一旦混用很容易出現錯誤。因為程式並不知道它是字串的邊界還是符號。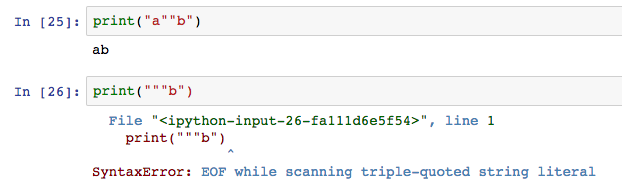
解決方法有兩種,一種是使用三引號,三引號代表整體引用,而且包含換行。第二種是引號前面加\,它是轉義字元,表示這個引號就是單純的字元。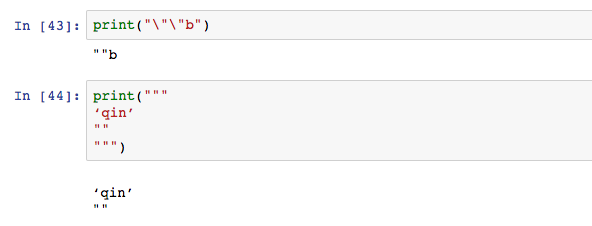
三引號也可以用來注釋,通常是大段的文字解釋,如果一句話,我們更習慣用#,#後面的內容均不會作為程式執行。
時間是特殊的數數值型別,它將結合datetime模組講解。
還有兩個常見的資料類型,布林值和空值。布林值是邏輯判斷值,只有True和False。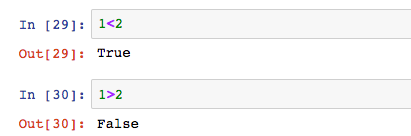
布林值在IF語句和資料清洗中經常使用,利用其過濾。布林值能和布林值運算,不過這裡是and、not、or作為運算子,Ttue and True = True,False and True = False,False and False = False,not True = False,True or False = True等。
空值是一個特殊的值,表示為None,None不等於0,0具有數學意義而None沒有,None更多表示該值缺失。
整數,浮點數,字串,布林值,空值就是Python常見的資料類型。Python3對中文的支持比較友好,所以大家可以用中文作為字串試一下print。
資料類型構成了變數的基礎,變數可以是任意的資料類型。想要用變數,必須先賦予變數一個值,這個過程叫賦值。
我首先給a賦予了一個整數值1,然後改變它為字串abc,變數在Python中沒有固定的數數值型別,這是Python最大的優點,所以它在資料分析中很靈活。這也是它被稱為動態語言的原因,相對應的叫靜態語言。
Python是大小寫敏感的語言,所以a和A是有區別的,這點請牢記。另外變數名盡可能使用英文,不要拼音,英文的可讀性是優於拼音的。
變數有兩種拼寫風格,一種叫駝峰,一種叫底線,以用戶ID為例。駝峰命名法為userId,以一串英文詞語user和id組成變數,第一個詞語的首字母小寫,第二個詞語開始的首字母均大寫。底線命名法為user_id,全部小寫,用_分割單詞。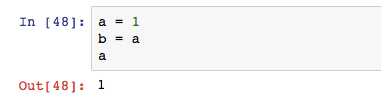
一個變數的值可以被賦予另外一個變數,如果b變數之前有另外一個值,那麼會被1覆蓋。呈從上而下的執行關係。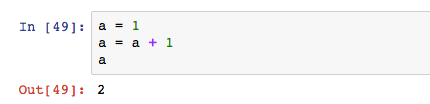
初看a = a + 1好像有邏輯問題,其實這涉及到了程式執行的先後順序,程式是先計算a+1的值得到2,然後將其賦予(覆蓋)了a。等號右邊的計算先於左邊,這是從右到左的邏輯關係。
有變數,自然有常量,常量是固定不變的量,可是在Python中沒有真正意義的常量,一切皆可變,它更多是習慣上的叫法,即一旦賦值,就不再改變了。
Python的基礎數學運算子號有+,-,*,/,//,%。前面四個就是加減乘除,其中除法的結果一定是浮點數。後面兩個符號是除法的特殊形式,//代表除法中取整數,%代表除法中取餘數。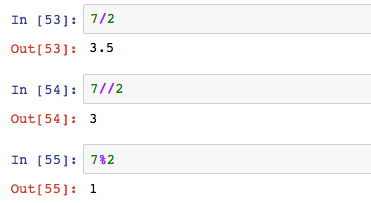
到這裡,新手部分已經講解完成。再來講講資料結構。
Python一共有三大資料結構,它是Python進行資料分析的基礎,分別是tuple元組,list陣列以及dict字典。本文透過這三者的學習,打下資料分析的基礎。
陣列是一個有序的集合,他用方括號表示。
num就是一個典型的陣列。陣列不限定其中的資料類型,可以是整數也可以是字串,或者是混合型。
陣列可以直接用特定的函數,函數名和Excel相近。
sum是求和,len則是統計陣列中的元素個數。
上述列舉的函數是陣列內整體元素的應用,如果我只想針對單一的元素呢?比如查找,這裡就要用到陣列的特性,索引。索引和SQL中的索引差不多,都是用來指示資料所在位置的邏輯指標。陣列的索引便是元素所在的序列位置。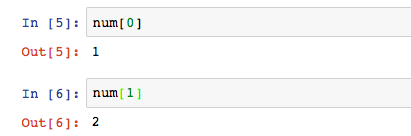
注意,索引位置是從0開始算起,這是程式設計語言的預設特色了。num[0]指數組的第一個元素,num[1]指數組的第二個元素。
我們用len()計算出了陣列元素個數是5,那麼它最後一個元素的索引是4。若是陣列內的元素特別多呢?此時查找陣列最後一位元的元素會有點麻煩。Python有一個簡易的方法,可以用負數表示,意為從最後一個數位計算索引。
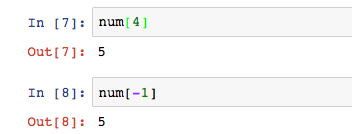
這裡的num[4]等價於num[-1],num[-2]則指倒數第二個的元素。
再來一個新問題,如何一次性選擇多個元素?例如篩選出陣列前三個元素。在Python中,用:表示範圍。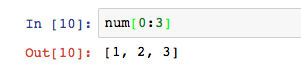
num[0:3]篩選了前三個元素,方括號左邊是閉區間,右邊是開區間,所以這裡是num[0],num[1]和num[2],並不包含num[3]。這個方法叫做切片。
上述是索引的特殊用法,[0:]表示從第0個索引開始,直到最後一個元素。[:3]表示從第一個元素開始,直到第3個索引。
負數當然也有特殊用法。[-1:]表示從最後一個元素開始,因為它已經是最後一個元素了,所以只返回它本身。[:-1]表示從第一個元素開始到最後一個元素。num[-2:-1]和num[-3:-1]大同小異。
我們已經瞭解陣列的基本概念,不過仍舊停留在查找,它不涉及資料的變化。工作中,更多需要操縱陣列,對陣列的元素進行添加,刪除,更改。
陣列透過insert函數插入,函數的第一個參數表示插入的索引位置,第二個表示插入的值。
另外一種方式是append,直接在陣列末尾添加上元素。它在之後講到反覆運算和迴圈時應用較多。
如果要刪除特定位置的元素,用pop函數。如果函數沒有選擇數值,預設刪除最後一個元素,如果有,則刪除數值對應索引的元素。
更改元素不需要用到函數,直接選取元素重新賦值即可。
到這裡,陣列增刪改查已經講完,但這只是一維陣列,一維陣列之上還有多維陣列。如果現在有一份資料是關於學生資訊,一共有三個學生,要求包含學生的姓名,年齡,和性別,應該怎麼用陣列表示呢?
有兩種思路,一種是用三個一維陣列分別表示學生的姓名,年齡和性別。
學生屬性被拆分成多個陣列,利用索引來表示其資訊,這裡的索引有些類似SQL的主鍵,透過索引查找到資訊。但是這種方法並不直觀,實際應用會比較麻煩,更好的方法是表示成多維陣列。
所謂多維陣列,是陣
列內再嵌套數組,圖中表示的是一個寬度為3,高度為3的二維陣列。此時student[0]返回的是陣列而不是單一值。這種方法將學生資訊合併在一起,比第一個案例更容易使用。
如果想選擇第一個學生的性別,應該怎麼辦呢?很簡單,後面再加一個索引即可。
現在嘗試快速創建一個多維陣列。
[0]*3將快速生成3個元素值為0的陣列,這是一種快捷操作,而[row]4則將其擴展成二維資料,因為是4,所以是34的結構。
這裡有一個注意點,當我們想更改多維陣列中的某一個元素而不是陣列時,這種方式會錯誤。
按照正常的想法,martix[1][0]將會改變第二個陣列中的第一個值為1,但是結果是所有陣列的第一個值都變成1。這是因為在matrix = [row] * 4操作中,只是創建3個指向row的引用,可以簡單理解成四個陣列是一體的。一旦其中一個改變,所有的都會變。
比較穩妥的方式是直接定義多維陣列,或者用迴圈間接定義。多維陣列是一個挺重要的概念,它也能直接表示成矩陣,是後續很多演算法和分析的基礎(不過在pandas中,它是另外一種形式了)。
tuple叫做元組,它和陣列非常相似,不過用圓括號表示。但是它最大的特點是不能修改。
當我們想要修改時就會報錯。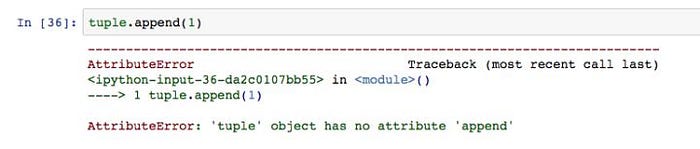
而選擇和陣列沒有差異。
元組可以作為簡化版的陣列,因為它不可更改的特性,很多時候可以作為常量使用,防止被篡改。這樣會更安全。
字典dict全稱dictionary,以鍵值對key-value的形式存儲。所謂鍵值,就是將key作為索引存儲。用大括弧表示。
圖中的’qinlu’是key,18是value值。key是唯一的,value可以對應各種資料類型。key-value的原理不妨想像成查找字典,拼音是key,對應的文字是value(當然字典的拼音不唯一)。
字典和陣列的差異在於,因為字典以key的形式存儲和查找,所以它的查詢速度非常快,畢竟翻字典的時候你只要知道拼音就能快速定位了。對dict資料結構,10個key和10萬個key在查找對應的value時速度沒有太大差別。
這種查找方式的缺點是佔用記憶體大。陣列則相反,查找速度隨著元素的增加逐漸下降,這個過程想像成程式在一頁頁的翻一本沒有拼音的字典,直到找到內容。陣列的優點是佔用的記憶體空間小。
所以陣列和字典的優缺點相反,dict是空間換時間,list是時間換空間,這是程式設計中一個比較重要的概念。實際中,資料分析師的工作不太涉及工程化,選用陣列或者字典沒有太嚴苛的限制。
細心的讀者可能已經發現,字典定義時我的輸入順序是qinlu,lulu,qinqin,而列印出來是lulu,qinlu,qinqin,順序變了。這是因為定義時key的順序和放在記憶體的key順序沒有關係,key-value透過hash演算法互相確定,甚至不同Python版本的雜湊演算法也不同。這一點應用中要避免出錯。
既然字典透過key-value對匹配查找,那麼它自然不能不用陣列的數值索引,它只能透過key值。
如果key不存在,會報錯。透過in方法,可以返回True或False,避免報錯。
dict和list一樣,直接透過賦值更改value。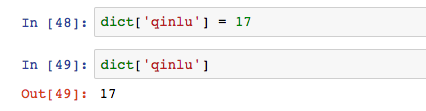
能不能更改key的名字?不能,key一旦確定,就無法再修改,好比字典定好後,你能修改字的拼音麼?
dict中刪除key和list一樣,透過pop函數。增加key則是直接賦予一個新的鍵值對。
dict的keys和values兩個函數直接輸出所有的key值和value值。如果要轉換成陣列,則再外面嵌套一個list函數。
items函數,將key-value對變成tuple形式,以陣列的方式輸出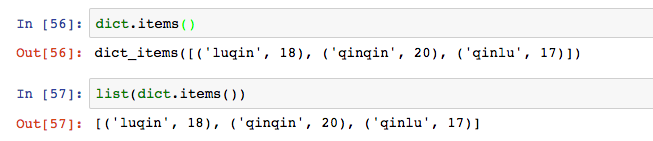
字典可以透過嵌套應用更複雜的資料格式,和NoSQL與JSON差不多。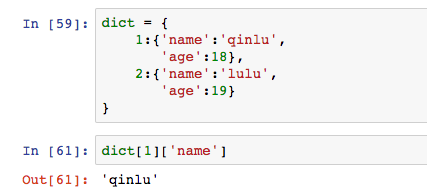
基礎的資料類型差不多了,更多函數應用大家可以網上自行查閱文檔,這塊掌握了,在資料清洗過程中將會非常高效,尤其是讀取Excel資料時。當然不要求滾瓜爛熟,因為後面將學習更加強大的Numpy和Pandas。
我是「數據分析那些事」。常年分享資料分析乾貨,不定期分享好用的職場技能工具。
 groots
groots
